剔除总结
0). 前言
最近实际做项目的时候发现对自身知识体系做整理的重要性,因此之后会慢慢做一些总结和思维导图,比如剔除、GI(GI方案、反射、AO等)、阴影等。本篇就以剔除开始;
a). 粗粒度剔除(CPU为主)
包括视锥剔除和遮挡剔除,为物体层面。
- 发生阶段:CPU应用阶段;
a.1). 视锥剔除
CPU阶段,物体的AABB包围盒与视锥体6个面分别作判断,剔除包围盒完全处于视锥体外的物体;
a.2). 遮挡剔除
a.2.1). 基于Occlusion Query
在深度测试时得到待剔除物体相关数据,在应用程序阶段执行。
- Occlusion Query: 在绘制命令执行前向GPU插入一条查询,在绘制结束后的某个时刻,从GPU将查询结果回读到内存中,得到某次DrawCall中通过Depth Test的Sample数量。
- 基础做法:
- 用Depth-Only的Pass将场景整体绘制一遍,将物体(的包围盒)深度写入Z-Buffer中;
- 使用物体的包围盒传入GPU进行Occlusion Query。如query得到的sample数大于0,则表示该物体(部分)可见,剔除掉Sample等于0的物体;
- 执行正常的渲染流程;
- 缺点:
- 对于复杂场景,Depth-Only也有较大的开销;
- 需要将查询结果读回内存(VRAM -> System RAM),需要走PCI-E(IMR架构);
- 常见的解决方法:回读上一帧Occlusion Query的结果,但可能导致一定的错误(但之后深度测试也可保证画面正确,因此此处出错只是增加了一部分渲染开销);
a.2.2). 基于Software Rasterization(软件剔除)
最早由Frostbite提出,用于战地3的剔除方案。
- CPU构造一个低分辨率的Z-Buffer,在其中绘制一些场景中较大的遮挡物(美术设定的一些大物体+地形);
- 在构造好的Z-Buffer上,绘制小物体的包围盒,执行类似Occlusion Query的操作进行剔除;

- 相比于基于Occlusion Query的方案:
- 优点: 纯CPU,集成方便,避免GPU Stall;
- 缺点: 需要美术设定大物体的遮挡,对CPU性能有一定消耗,对于CPU负载大的场景可能造成负优化;
a.3). PVS(Potentially Visible Set)
潜在可见集。PVS的基本思想为:离线的把场景划分成许多个块,这些分块的划分可能是均匀的3D网格,也能是自适应大小的3D网格。完成网格划分之后会计算网格之间的可见性或场景中每个物体对当前网格的可见集用于之后剔除。

a.4). Portal
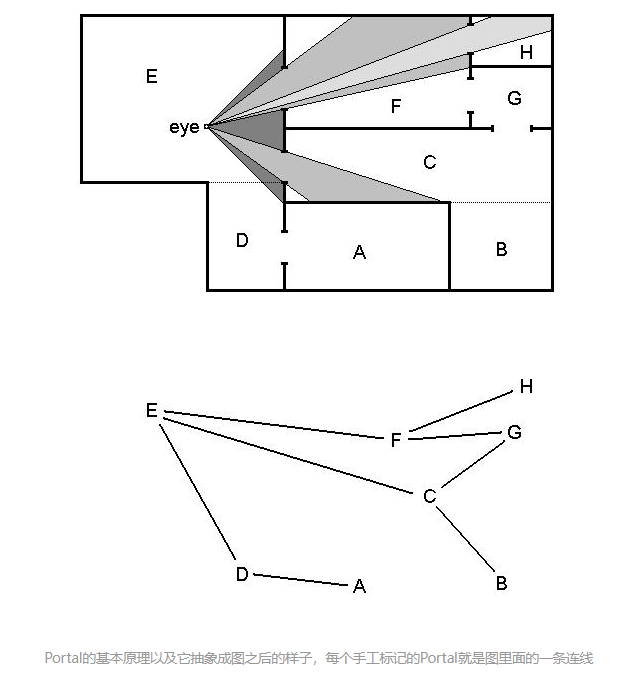
这种方式也是将场景划分成Cell,不同的是,烘焙时保存的是每两个相邻Cell之间的连通性。
这样,在运行时,根据摄影机所在的位置的Cell和观察方向,就可以根据Cell间的连通性信息,快速计算出目标物体是否处于可见范围内。Unity自带的遮挡剔除就是使用改方法(Umbra)
优点(相较于PVS):可以剔除动态物体,同时提供了些许的静态遮挡物体变化的灵活性(如有扇可以开关的门,当门被打开后,就可以将门两侧的Cell的连通打开);
缺点: 相较于视锥剔除的通用性来说其应用场景更受限制,且需要手工标定;
a.5). 层级剔除(Layer Culling Mask)
对特定Layer的物体进行选择性剔除
a.6). 距离剔除(LOD同理)
b). 硬件剔除(GPU为主)
b.1). Hiz Culling
- 发生阶段: 在Geometry Shader得到待剔除物体,在下一Pass的Vertex Shader渲染。剔除可通过Compute Shader实现;
- 具体实现:
- 拿到上一帧深度buffer,利用深度buffer构造深度的mipmap,每一层mip中像素的值是上一级mip中对应位置的深度最大值(最远处);
- 将场景物体分为:上一帧已有物体(集合1)、当前帧新增物体(集合2);
- 对于集合1,根据其包围盒在屏幕上的大小取对应级别的Hi-z map图,通过深度比较进行剔除;
- 根据3剔除结果绘制集合1,更新z buffer;
- 利用新的z buffer建立mipmap深度图,对集合2进行剔除;
- 绘制集合2的物体,更新z buffer;
b.2). Clipping & Backface Culling
Clipping处于顶点被转换到NDC后,Backface Culling处于图元装配后根据顶点绕序进行剔除;
b.3). Early-Z
发生阶段: 光栅化后,FS前(Z-Cull后);
对象: 2x2 Pixel Quad;
- Tips:
- 深入GPU硬件架构及运行机制 - 0向往0 - 博客园 (cnblogs.com)
- 解释了Early-Z为何需要有Late-Z,除了失效情况,还可解决深度数据冲突(depth data harzard)
- 深入GPU硬件架构及运行机制 - 0向往0 - 博客园 (cnblogs.com)
b.4). Z-Cull
发生阶段: 光栅化后,FS前(Early-Z前);
对象:较为粗粒度,为Pixel Tile(如8*8的像素块)
b.5). Depth Test
发生阶段: 逐片元操作(输出合并);
对象: fragment;
深入GPU硬件架构及运行机制 - 0向往0 - 博客园 (cnblogs.com)
- 解释了Early-Z为何需要有Late-Z,除了失效情况,还可解决深度数据冲突(depth data harzard)
b.6). HSR/Forward Pixel Kill
TBDR架构中,光栅化后,light pass前。
- 对比于Early-Z: early-z需要物体排序,对于不透明物体如果从后往前排序,那early-z无法解决overdraw。而HSR/FPK,可以起到完全解决overdraw(在全部fragment生成后,进入到FS前筛选出最前面的fragment);
c). 其他剔除
Forward+ 的 Light culling
……