半透明排序总结
OIT(Order Independent Transparency)
a). Depth Peeling(深度剥离)

- 优点:
- 遍历都是无序的,也就是说不依赖对物体的排序,所以也就不会出现半透明排序的问题;
- 基本无硬件要求
- 缺点:
- 需要重复多次Pass进行深度剥离,性能开销大;
b). Per-Pixel Linked Lists(L.L)
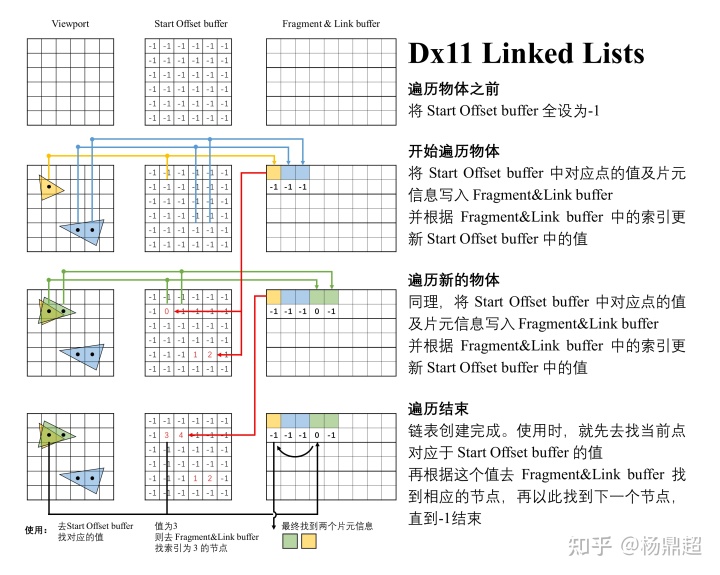
在 Pixel Shader 中使用两个可写的纹理(DX11,SM 5.0,UAV),一个屏幕大小的链表头纹理(Start Offset buffer),一个屏幕大小 N 倍的链表节点纹理( Fragment & Link buffer)。链表头纹理的每个像素存储每个像素链表在节点纹理中的偏移量。
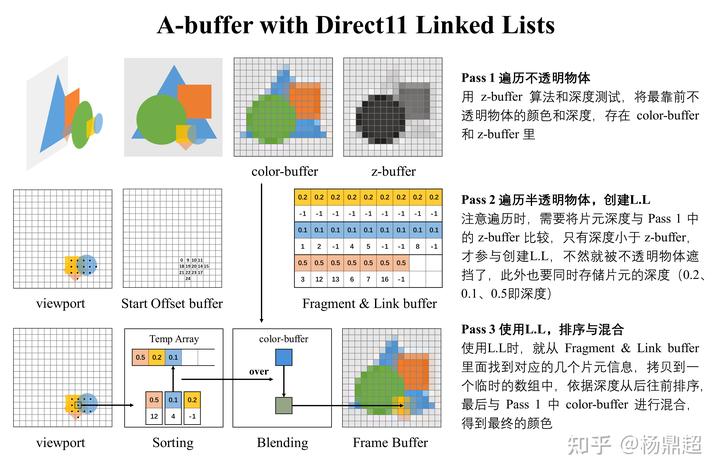
- 优点:
- 比 Depth Peeling 快了很多。性能开销也比 Depth Peeling 更加节省
- 缺点:
- 节点纹理具体需要多大无法事先做准确的预估,因此显存的具体消耗不可控(因此多用于离线渲染)
- 仅支持DX11、SM5.0以上;
c). MLAB(Multi-Layer Alpha Blending)
不像 A-buffer 对每一层片元都进行存储,而是根据深度 z 将片元划分为多组,先对每组的片元混合后,只存储这一组的颜色、透明度和深度,最后对各组按顺序进行混合。
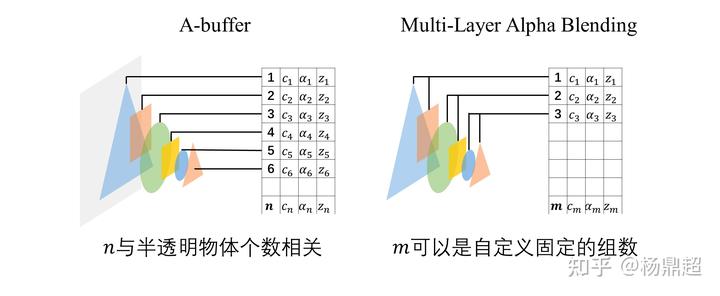
- 优点: 内存大小固定,无L.L的问题;
- 缺点: 对于单个层内,不透明顺序未知,可能造成Artifact;
d). Weighted Sum & Weighted Averaging(WS & WA)
从传统的“逐层 over”的算法出发,列出其展开式,分析其中不依赖排序的因子,从而进行简化近似。
- 优点:开销小;
- 缺点:在alpha较大时有明显的Artifact;
e). Adaptive Transparency
Adaptive Transparency,简称 AT,是 Intel 提出的一种 OIT 技术。其核心思想是通过修改经典混合公式本身来改进 Per-Pixel Linked Lists 方法的内存和性能问题。
- 引入能见度函数(阶梯下降);
其他做法
a). PreZ(详见百人计划3.5 Early-z和Z-prepass)
第一个Pass(Z-Prepass):仅写入深度;
第二个Pass:关闭深度写入,并将深度测试比较符改为等于;
b). 顶点顺序
模型保存为OBJ(FBX等),其中每个顶点都有顶点编号,引擎渲染就会按顶点编号的顺序进行渲染。
对于一个多层的面,可以先创建内部的点,在创建外部的点,保证内部顶点编号小于外部,使其先渲染内部再渲染外部。